- bo: programme officiel
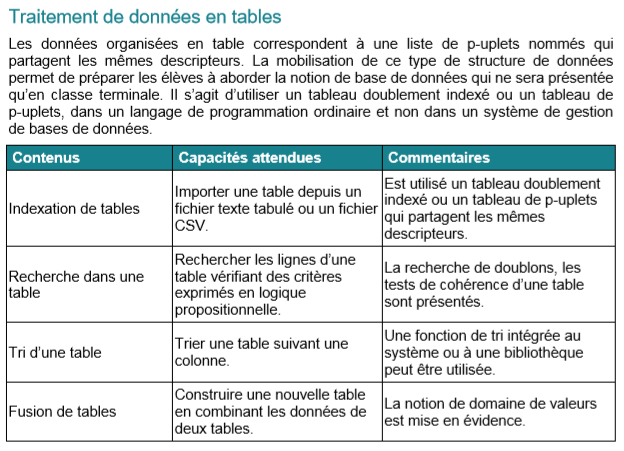
Contexte : Les élève de première NSI 1 du lycée Mauriac ont suivi une année de cours avec quelques élèves de Poudlard. Les matières suivies sont : ‘Potions’, ‘Botanique’, ‘étude des Moldus’, ‘Sortilèges’, ‘Vol sur Balai’.
Par soucis d’équité les notes entre 0 et 20 sont tirées de façon aléatoire.
L’années est constituée de trois trimestres.
1) Fichier csv et tableur
Ouvrir le fichier poudlard.csv avec notepad++ ou un autre éditeur de texte et justifier l’appellation de l’extension .csv du fichier
La virgule est le séparateur par défaut mais on peut rencontrer aussi d’autres séparateurs.
Le sigle CSV signifie Comma-Separated Values et désigne un fichier texte dont les valeurs sont séparées par des virgules.
La virgule est le séparateur par défaut mais il existe d’autres séparateurs
Vous pouvez ouvrir le fichier avec n’importe quel éditeur de texte et avec le bloc note ou notepad++ par exemple
- Quel est le séparateur utilisé ?
- Que contient la première ligne?
- Pourquoi trouve on parfois des virgules qui se suivent ?
Vous pouvez aussi ouvrir le fichier avec un tableur
LibreOffice vous proposera des options pour l’ouvrir correctement. Vous pouvez en particulier choisir le séparateur
Sur Excel il faut d’abord ouvrir le tableur puis aller dans l’onglet données
2) Fichier csv et python
Corrigé et compléments à tester à comprendre et commenter
Comparez en testant les deux méthodes ci-dessous pour lire un fichier csv
Fichier = open('poudlard.csv','r')
eleves=Fichier.readlines()
Fichier.close()
import csv
eleves=[]
with open('216.csv',newline='')as csvfile:
s=csv.DictReader(csvfile,delimiter=';')
for line in s:
eleves.append(dict(line))
En utilisant vos connaissances sur les listes et les dictionnaires complétez la variable eleves en attribuant toutes les notes de façon aléatoire.
3)Projet 1
pandas est la librairie python de référence pour manipuler les données. Elle permet de manipuler les données sous forme de tables (DataFrame) et de les exporter avec différents formats. Elle permet aussi de créer facilement des graphes avec matplotlib par exemple
https://pandas.pydata.org/docs/user_guide/10min.html
Les activités qui suivent doivent être réalisées dans un même notebook sur colaboratory. Les codes sont fournis
Il suffit de les tester les comprendre puis commenter votre code pour pouvoir le réexploiter dans le projet Vortex.
3-1) Lecture des fichiers csv
Vous aurez besoin des deux fichiers ci-dessous pour réaliser l’activité :
Exécuter les deux lignes de code ci-dessous puis importer les
deux fichiers csv que vous avez récupéré grâce aux liens ci-dessus.
from google.colab import files data_to_load = files.upload()
On peut lire le fichier csv en précisant l’encodage et le type de séparateur. On crée un objet de type dataframe (pandas.core.frame.DataFrame)
Vous pouvez le vérifier en demandant le type de l’objet poudlard que vous allez créer:
import pandas as pd
poudlard= pd.read_csv('poudlard1.csv',encoding = "ISO-8859-1",sep=";")
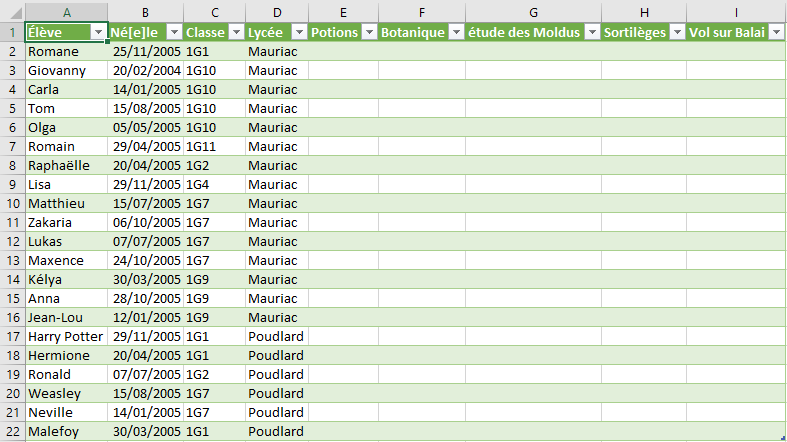
Vous pouvez afficher l’objet poudlard ou quelques lignes seulement.5 lignes sont affichées par défaut avec la fonction head().Vous pouvez préciser le nombre n de lignes souhaitées avec head(n)
poudlard.head()
NaN correspond aux données manquantes Not a Number
Vous pouvez accéder aux champs de la table (première ligne du fichier csv:
Vous pouvez accéder aux champs de la table (première ligne du fichier csv:
poudlard.columns
On peut accéder au contenu de la ligne 16 (17 du fichier csv) avec la méthode « loc »
poudlard.loc[16]
On peut sélectionner la colonne avec son indice
poudlard.loc[16][0]
ou avec l’étiquette de la colonne
poudlard.loc[16]['Élève']
3-2) Recherche et ajout de données manquantes
La méthode isnull() permet de rechercher les données manquantes. On peut ajouter head() pour limiter l’affichage
poudlard.isnull().head()
Nous savions déjà qu’il manquait toutes les notes. La méthode isnull() a traduit les données par True ou False.
Nous allons remplacer les données manquantes en générant des notes aléatoires. Vous compléterez le code en remplaçant les……
import random
matieres=['Potions', 'Botanique','étude des Moldus', 'Sortilèges', 'Vol sur Balai']
for val in .....:
poudlard[val]=[random.randint(10,20) for i in range(....)]
poudlard.head()
Vérifiez que les notes ont bien été attribuées
Nous allons modifier la table en ajoutant une colonne de moyennes
matieres=['Potions', 'Botanique','étude des Moldus', 'Sortilèges', 'Vol sur Balai'] poudlard['moyenne']=poudlard[matieres].mean(axis='columns') poudlard.head()
3-3) Regroupement de catégories et agrégation de données
L’objectif est de créer deux tables en séparant les élèves de Mauriac et de Poudlard.
Il nous faudra la moyenne générale pour Mauriac et pour Poudlard.
exemple de résultat attendu

La méthode groupby() permet de séparer les données.
On peut pour cela commencer à rechercher les critères uniques d’une colonne
poudlard['Lycée'].unique().tolist()
On peut ensuite créer les groupes
classes= poudlard.groupby("Lycée")
group_mauriac= classes.get_group('Mauriac')
group_poudlard= classes.get_group('Poudlard')
Vous pouvez par exemple vérifier que group_poudlard contient les élèves de Poudlard
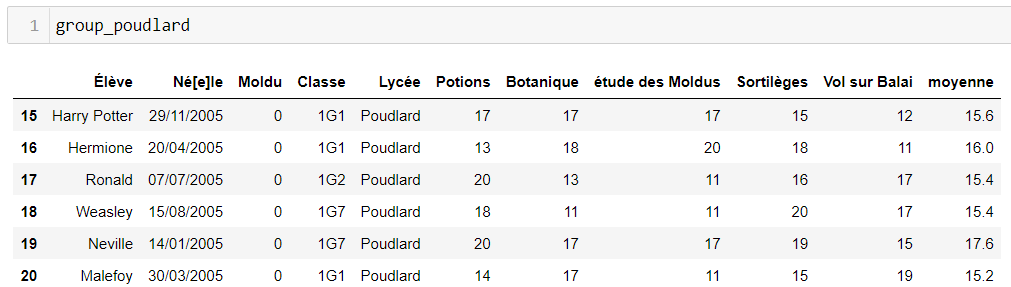
En réalité on peut sans passer par l’étape précédente Agréger les données en choisissant le critère lycée et en calculant la moyenne des moyennées des données agrégées.
poudlard.groupby(['Lycée'])["moyenne"].agg( "mean").round(1)
4)Projet 2
Il s’agit encore une fois de préparer le projet Vortex .
Deux élèves ont abusé de leurs pouvoirs en supprimant leurs moyennes ou en modifiant la moyenne générale. vous disposez du fichier csv ci-dessus . Les deux élèves sont renvoyés du lycée. On doit trouver les deux lignes modifiées (filtrer ) et les supprimer.
On commence par lire le fichier
import pandas as pd
nsi_hack= pd.read_csv('nsi_hack.csv',encoding = "ISO-8859-1",sep=";")
On peut s’apercevoir qu’un élève n’a pas de moyenne. Recherchons le
nsi_hack[nsi_hack['moyenne'].isnull()]
On peut s’apercevoir qu’une des moyennes égale à 20 n’est pas cohérente. On peut la rechercher aussi
nsi_hack[nsi_hack['moyenne']=="20"]
On peut supprimer les deux lignes avec la méthode drop()
nsi_hack.drop(nsi_hack[nsi_hack['moyenne']=="20"].index) nsi_hack.drop(nsi_hack[nsi_hack['moyenne'].isnull()].index)
On peut aussi appliquer des fonctions à une colonne ou une ligne. Nous allons essayer de modifier la colonne né le en l’affichant de façon plus explicite.
Il s’agit de tester les codes de comprendre les traitements effectués pour pouvoir les appliquer dans une autre situation.