Lien vers le colaboratory: https://colab.research.google.com/drive/1X28xcBuPu3EeP6C8ub2GVJk6ame6rOdC?usp=sharing Pour diviser la colonne StartDateTime en 2 colonnes: https://datascienceparichay.com/article/pandas-split-column-by-delimiter/ Solution proposée par le groupe de lukas. https://colab.research.google.com/drive/1LRooPtjzqsaD63kWGjtlbJTyNSZSiHha?usp=sharing Solution proposée par le professeur: https://colab.research.google.com/drive/1luH2hNr21-1fyOAIBsaY_q7TQG9KoGsT?usp=sharing
Pandas est une bibliothèque python qui permet la manipulation et l’analyse de données sous forme de tables, et permet également de les représenter sous des graphes.

On a un fichier csv avec des noms, des dates de naissance, des lycées, des classes et différentes matières. Les matières ont des notes manquantes. On peut ajouter des valeurs manquantes à des dictionnaires de cette manière; ici les notes sont ajoutés et sont aléatoires entre 10 et 20.
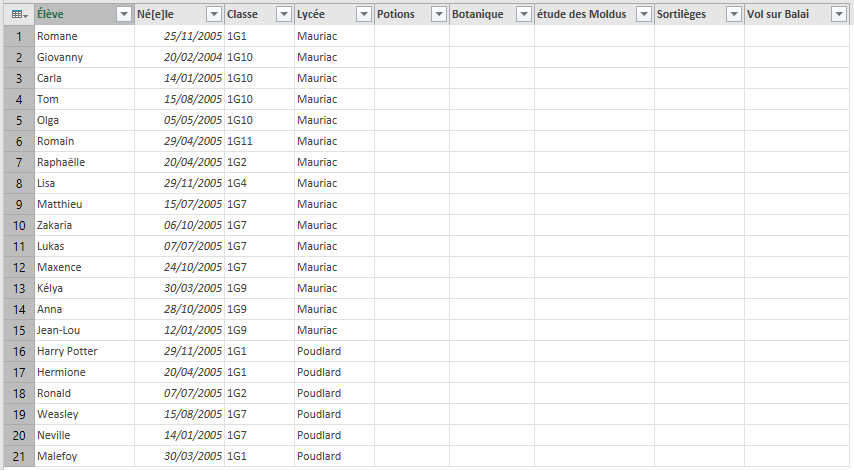
Afin d’ouvrir correctement un fichier csv, il faut ouvrir excel, cliquer sur « Données », puis « Nouvelle requête » et puis « à partir d’un ficher csv ». Après ça on peut choisir un séparateur, filtrer les données, les trier..

La première méthode consiste à ouvrir le fichier extraire ses données pour les mettre dans une liste. La deuxième méthode consiste à ouvrir le fichier et extraire ses données pour les mettre dans une liste de dictionnaires.