Le k-NN est le diminutif de k Nearest Neighbors. Le k-NN est un algorithme servant autant pour la classification que pour la régression. Nearest Neighbors signifie en français « plus proches voisins, voisins les plus proches » car le principe de ce modèle consiste en effet à choisir les k données les plus proches du point étudié afin d’en prédire sa valeur.
Exemple du fonctionnement de cet algorithme :
Ci-dessous est représenté un jeu de données d’entraînement avec deux classes, la classe rouge et la classe bleu. L’input (entrée, saisie) est donc bidimensionnel (à deux dimensions) ici, et la target (cible) est la couleur à classer.
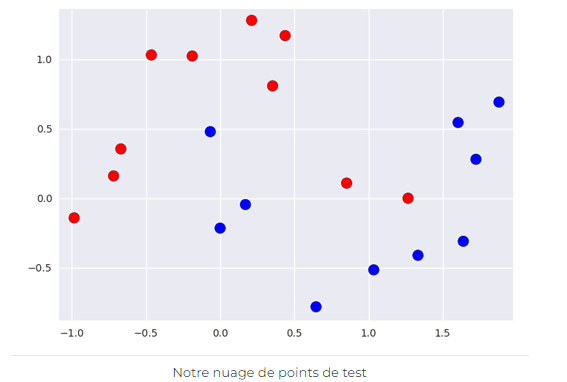
Si l’on a une nouvelle entrée dont on veut prédire la classe, comment pourrait-on faire ?
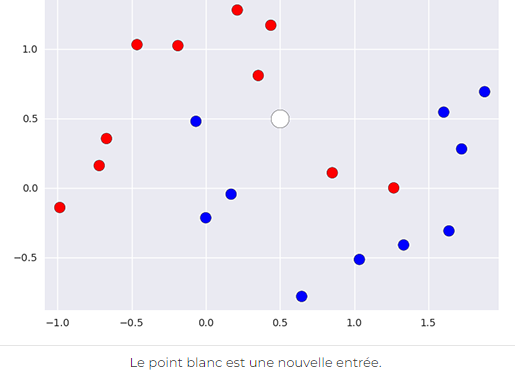
Il suffit simplement de regarder les k voisins (ici, les points) les plus proches du point étudié et de regarder quelle classe constitue la majorité de ces points, afin d’en déduire la classe (rouge ou bleu) du nouveau point. Par exemple, ici, si on utilise le 5-NN, on peut prédire que le nouveau point appartient à la classe rouge puisqu’elle possède 3 points rouges et 2 points bleus dans son entourage.
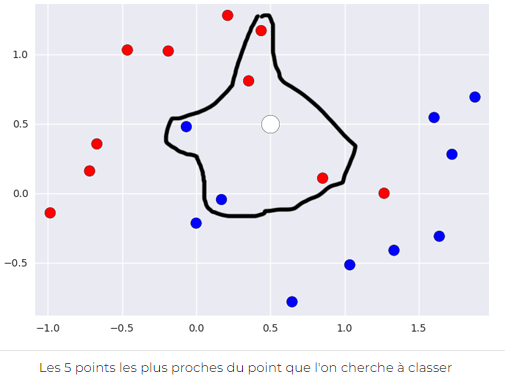
On peut facilement en déduire les zone rouge et bleue, où les points qui se situeront dans la zone seront respectivement classés comme rouge ou bleu (voir ci-dessous).
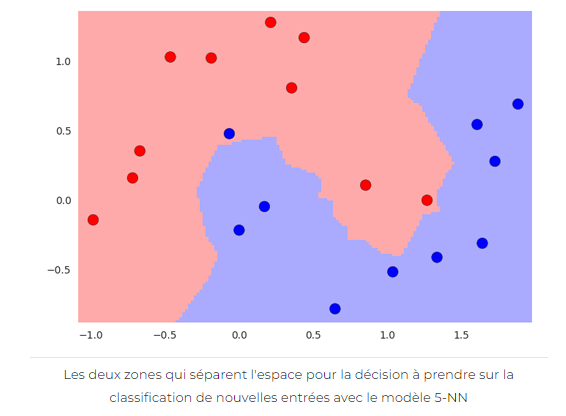
Utilisation de k-NN sur un jeu de données.
Premièrement, voici une brève explication du jeu de données utilisé : ce jeu est un dataset très célèbre, appelé MNIST. Il est constitué d’un ensemble de 70000 images 28×28 pixels en noir et blanc annotées du chiffre correspondant (entre 0 et 9). L’objectif de ce jeu de données était de permettre à un ordinateur d’apprendre à reconnaître des nombres manuscrits automatiquement (pour lire des chèques par exemple). Ce dataset utilise des données réelles qui ont déjà été prétraitées afin d’être plus facilement utilisables par un algorithme.

L’objectif est donc d’entraîner un modèle qui est capable de reconnaître les chiffres présent sur ce type d’images. Par chance, ce jeu de données est téléchargeable directement à partir d’une fonction scikit-learn. 😇 On peut donc directement obtenir ce dataset via un appel de fonction :

Voici le code permettant d’atteindre cet objectif :
https://colab.research.google.com/drive/1UVVeA-xdnacW80bJA5zRzck9ehOjN6Y-?usp=sharing
Aucune réponse