
k-NN = k Nearest Neighbors, les plus proches voisins en français
Cet algorithme sert à choisit les k données les plus proches
Fonctionnement:
Exemple visuel :
Ca représente ici un jeu de données d’entraînement avec deux classes, rouge et bleu. L’input est donc bidimensionnel ici, et la target est la couleur à classer.
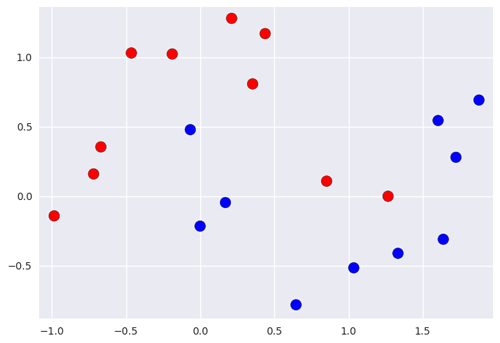
Si on veut une nouvelle entrée dont on veut prédire la classe, On va se concentrer sur les points plus proches et regarder quelle classe constitue la majorité de ces points afin de déduire la classe du nouveau point:
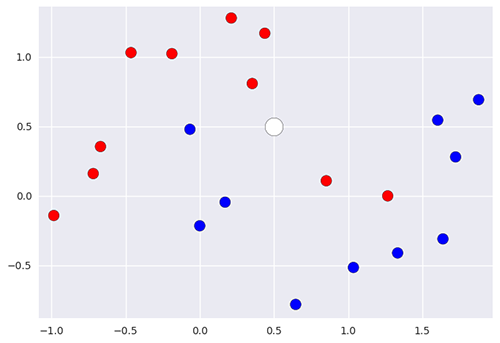
Par exemple, ici, si on utilise le 5-NN, on peut prédire que la nouvelle donnée appartient à la classe rouge puisqu’elle a 3 rouges et 2 bleus dans son entourage.

On peut facilement en déduire les zone rouge et bleue, où les points qui se situeront dans la zone seront respectivement classés comme rouge ou bleu.

Les données et la problématique
D’abord, parlons du jeu de données que nous allons utiliser. C’est un dataset très célèbre, appelé MNIST. Il est constitué d’un ensemble de 70000 images 28×28 pixels en noir et blanc annotées du chiffre correspondant (entre 0 et 9). L’objectif de ce jeu de données était de permettre à un ordinateur d’apprendre à reconnaître des nombres manuscrits automatiquement (pour lire des chèques par exemple). Ce dataset utilise des données réelles qui ont déjà été pré-traitées pour être plus facilement utilisables par un algorithme.

On va entraîner un modèle qui sera capable de reconnaître les chiffres écrits sur ce type d’images.
L’objet mnist contient deux entrées principales, data et target. On peut les afficher :

-
datacontient les images sous forme de tableaux de 28 x 28 = 784 couleurs de pixel en niveau de gris, c’est-à-dire que la couleur de chaque pixel est représentée par un nombre entre 0 et 16 qui représente si celle-ci est proche du noir ou pas (0 = blanc, 16 = noir). -
targetqui contient les annotations (de 1 à 9) correspondant à la valeur « lue » du chiffre.

Échantillonner pour faciliter le travail
le datatest est relativement petit mais trop gros pour le modèle k-NN pour obtenir rapidement les résultats. On peut utiliser pour ça un sampling et travailler sur seulement 5000 données

Le tableau d’indices généré par randit peut contenir des doublons. Donc on peut en retrouver souvent dans nos données.
Vu qu’on va prendre seulement 5000 échantillons sur 7000, le risque est faible.
Séparer training / testing set:
Une fois que le dadatest est chatcgé, on va le jeu de données en training set et testing set.
dans cet exemple les annontations cibles sont appelées « y » et les images d’exemple « x »
On peut créer un premier classifieur 3-NN, donc qui prend en compte les 3 plus proches voisins pour la classification


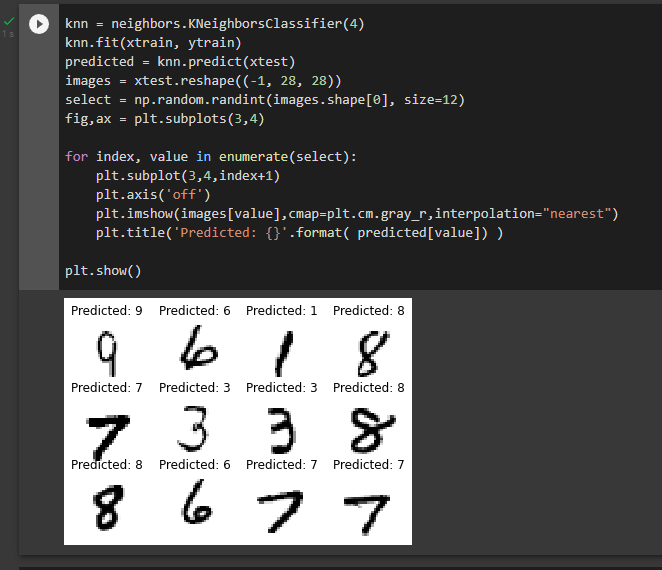
Pour pouvoir un peu mieux comprendre les erreurs effectuées par le classifieur, on peut aussi afficher un extrait des prédictions erronées :
