
Vidéo pour mieux comprendre l’algorithme k-NN : https://www.youtube.com/watch?v=HVXime0nQeI


Lien Openclassroom : https://openclassrooms.com/fr/courses/4011851-initiez-vous-au-machine-learning/4022441-entrainez-votre-premier-k-nn
Lien des tests GoogleColab : https://colab.research.google.com/drive/1Gezch3iXfSzYDYiTpQSabGkbEKJkqllF
Algorithme k-NN :
k-NN est le diminutif de K Nearest Neighbors.
L’algorithme k-NN peut servir autant pour la classification que pour la régression. Il est surnommé « nearest neighbors » car le principe de ce modèle consiste en effet à choisir les k données les plus proches du point étudié afin d’en prédire sa valeur.
Comment fonctionne k-NN ?
Voici un petit exemple visuel afin de comprendre le fonctionnement de l’algorithme :
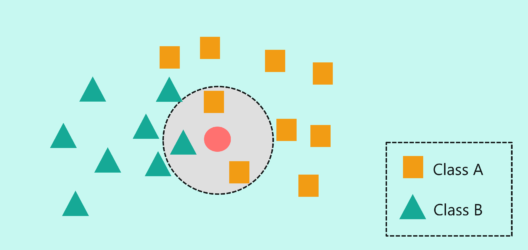
Ci-dessous, un jeu de données d’entraînement avec deux classes, rouge et bleu. L’input est donc bidimensionnel ici, et la target est la couleur à classer.
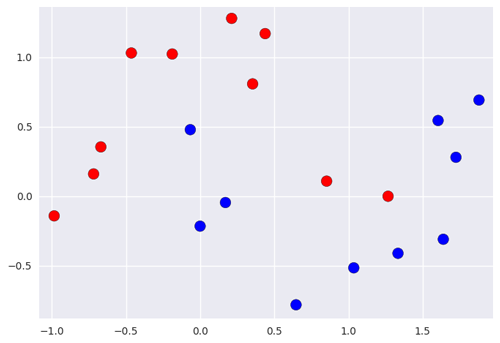
Si l’on a une nouvelle entrée dont on veut prédire la classe, comment pourrait-on faire ?
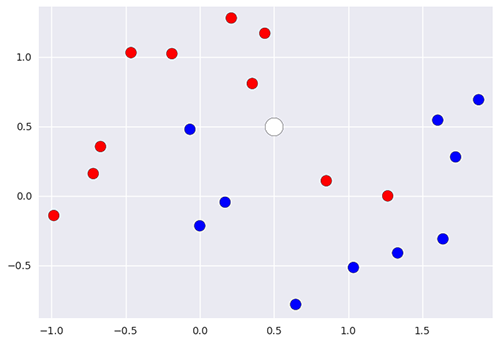
On va simplement regarder les k voisins les plus proches de ce point et regarder quelle classe constitue la majorité de ces points, afin d’en déduire la classe du nouveau point. Par exemple, ici, si on utilise le 5-NN, on peut prédire que la nouvelle donnée appartient à la classe rouge puisqu’elle a 3 rouges et 2 bleus dans son entourage.
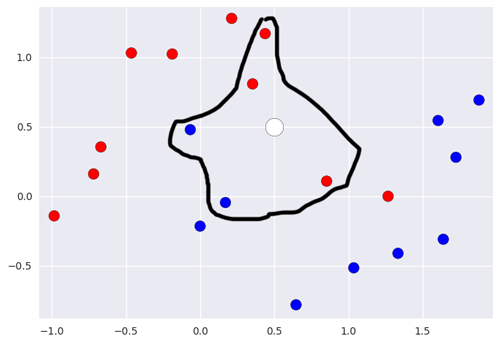
On peut facilement en déduire les zone rouge et bleue, où les points qui se situeront dans la zone seront respectivement classés comme rouge ou bleu.
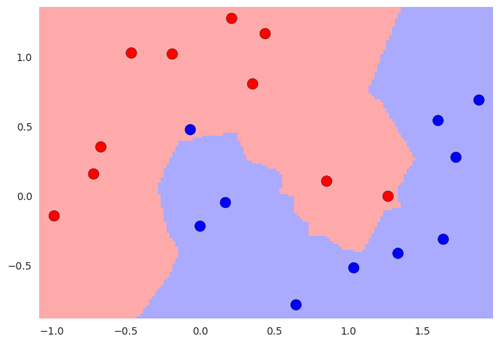
le k-NN est un type spécial d’algorithme qui n’utilise pas de modèle statistique. Il est « non paramétrique » et il se base uniquement sur les données d’entraînement. Ce type d’algorithme est appelé memory-based. A contrario, la régression linéaire est paramétrique, de paramètre θ et ne va donc pas avoir besoin de conserver toutes les données pour effectuer des prédictions, mais seulement θ.
C’est d’ailleurs un autre inconvénient de l’algorithme k-NN, il doit conserver toutes les données d’entraînement en mémoire (memory-based) et donc convient aux problèmes d’assez petite taille.
Il va s’agir maintenant de choisir le bon nombre de voisins k, en fonction de l’erreur de généralisation du modèle.
Utiliser k-NN sur un vrai jeu de données :
Les données et la problématique
D’abord, parlons du jeu de données que nous allons utiliser. C’est un dataset très célèbre, appelé MNIST. Il est constitué d’un ensemble de 70000 images 28×28 pixels en noir et blanc annotées du chiffre correspondant (entre 0 et 9). L’objectif de ce jeu de données était de permettre à un ordinateur d’apprendre à reconnaître des nombres manuscrits automatiquement (pour lire des chèques par exemple). Ce dataset utilise des données réelles qui ont déjà été pré-traitées pour être plus facilement utilisables par un algorithme.

Notre objectif sera donc d’entraîner un modèle qui sera capable de reconnaître les chiffres écrits sur ce type d’images. Par chance, ce jeu de données est téléchargeable directement à partir d’une fonction scikit-learn. 😇 On peut donc directement obtenir ce dataset via un appel de fonction :
from sklearn.datasets import fetch_openml
mnist = fetch_openml('mnist_784', version=1)
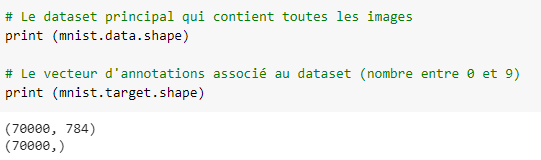
L’objet mnist contient deux entrées principales, data et target. On peut les afficher :
# Le dataset principal qui contient toutes les images print (mnist.data.shape) # Le vecteur d'annotations associé au dataset (nombre entre 0 et 9) print (mnist.target.shape)
-
datacontient les images sous forme de tableaux de 28 x 28 = 784 couleurs de pixel en niveau de gris, c’est-à-dire que la couleur de chaque pixel est représentée par un nombre entre 0 et 16 qui représente si celle-ci est proche du noir ou pas (0 = blanc, 16 = noir). -
targetqui contient les annotations (de 1 à 9) correspondant à la valeur « lue » du chiffre.
Échantillonner pour faciliter le travail :
Le dataset est relativement petit mais, pour le modèle k-NN, il est déjà trop gros pour obtenir rapidement des résultats. On va donc effectuer un sampling et travailler sur seulement 5000 données :
import numpy as np sample = np.random.randint(70000, size=5000) data = mnist.data.values[sample] target = mnist.target.values[sample]
Ne pas oublier import numpy as np ! 🙆
Séparez training / testing set
Une fois notre dataset chargé, comme nous l’avons vu dans le chapitre précédent, nous allons séparer le jeu de données en training set et testing set.
J’ai ici appelé les images d’exemple « X » et les annotations cibles « y » :
from sklearn.model_selection import train_test_split xtrain, xtest, ytrain, ytest = train_test_split(data, target, train_size=0.8)
On peut créer un premier classifieur 3-NN, c’est-à-dire qui prend en compte les 3 plus proches voisins pour la classification. Pour cela, on va utiliser l’implémentation de l’algorithme qui existe dans la librairie scikit-learn :
from sklearn import neighbors knn = neighbors.KNeighborsClassifier(n_neighbors=3) knn.fit(xtrain, ytrain)

Testons à présent l’erreur de notre classifieur. La méthode score effectue exactement ça : tester les performances de prédiction d’un classifieur dans lequel on passe un jeu de données annoté — dans notre cas le jeu de données de test. Il renvoie ainsi le pourcentage de prédiction véridique trouvée par le classifieur.
error = 1 - knn.score(xtest, ytest)
print('Erreur: %f' % error)
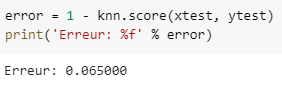
Optimisation du score sur les données test
Pour trouver le k optimal, on va simplement tester le modèle pour tous les k de 2 à 15, mesurer l’erreur test et afficher la performance en fonction de k :
import matplotlib.pyplot as plt
errors = []
for k in range(2,15):
knn = neighbors.KNeighborsClassifier(k)
errors.append(100*(1 - knn.fit(xtrain, ytrain).score(xtest, ytest)))
plt.plot(range(2,15), errors, 'o-')
plt.show()
Ne pas oublier import matplotlib.pyplot as plt ! 🙇
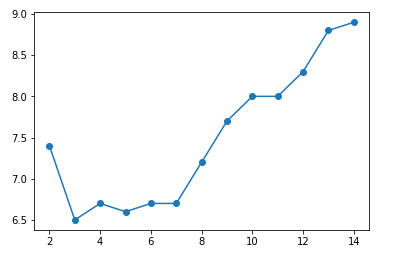
Comme on peut le voir, le k-NN le plus performant est celui pour lequel k = 4. On connaît donc notre classifieur final optimal : 4-nn. Ce qui veut dire que c’est celui qui classifie le mieux les données, et qui donc dans ce cas précis reconnaît au mieux les nombres écrits à la main.
À titre d’exemple, vous pouvez afficher les prédictions du classifieur sur quelques données.
# On récupère le classifieur le plus performant
knn = neighbors.KNeighborsClassifier(4)
knn.fit(xtrain, ytrain)
# On récupère les prédictions sur les données test
predicted = knn.predict(xtest)
# On redimensionne les données sous forme d'images
images = xtest.reshape((-1, 28, 28))
# On selectionne un echantillon de 12 images au hasard
select = np.random.randint(images.shape[0], size=12)
# On affiche les images avec la prédiction associée
fig,ax = plt.subplots(3,4)
for index, value in enumerate(select):
plt.subplot(3,4,index+1)
plt.axis('off')
plt.imshow(images[value],cmap=plt.cm.gray_r,interpolation="nearest")
plt.title('Predicted: {}'.format( predicted[value]) )
plt.show()

Pour pouvoir un peu mieux comprendre les erreurs effectuées par le classifieur, on peut aussi afficher un extrait des prédictions erronées :
# on récupère les données mal prédites
misclass = (ytest != predicted)
misclass_images = images[misclass,:,:]
misclass_predicted = predicted[misclass]
# on sélectionne un échantillon de ces images
select = np.random.randint(misclass_images.shape[0], size=12)
# on affiche les images et les prédictions (erronées) associées à ces images
for index, value in enumerate(select):
plt.subplot(3,4,index+1)
plt.axis('off')
plt.imshow(misclass_images[value],cmap=plt.cm.gray_r,interpolation="nearest")
plt.title('Predicted: {}'.format(misclass_predicted[value]) )
plt.show()
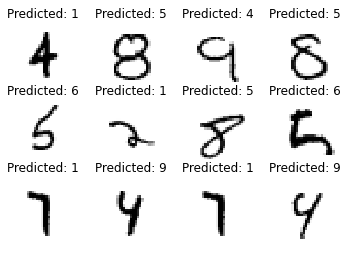
En résumé : on vient de voir sur un algorithme simple comment l’entraîner sur des données pour ensuite optimiser les paramètres de cet algorithme à l’aide d’un jeu de données test.
Aucune réponse