I) Code ASCII
1)Définition
On peut décomposer le mot ASCII, on peut le traduire actuellement par une décomposition américaine : Américain Standard Code for Information Interchange. Il a été créer en 1961, initialement présent pour le codage, il s’agit d’un jeu de 128 caractères codés sur 7 bits soit environ 1 octet.
Ainsi on peut créer une liste pour développer le code et les caractères présents dans ce dernier à savoir 128 caractères seront dévoilé. Seul les caractères spéciaux seront présentés sous forme hexadécimal.
2) Exemples
Comme on peut le voir sur le code ci-dessous, les deux premières lignes de codes sont sous forme hexadécimal :
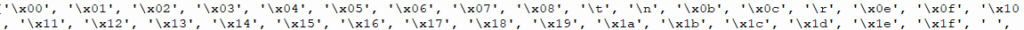
II)Code semblables à ASCII : ISO 8859-1
1)Définition
ISO signifie International Standards Organizations, avec une première version 1986, ISO 8859-1 est composé de 1 octet précisément donc 8 bits mais encore 191 charactères. Cet encodage reprend l’ascii pour les caractères imprimables , ce code utilise l’alphabet latin-1 composée alors de 191 charactères.
2)Exemples
Différentes possibilités sont possibles et disponible à l’essai, exploiter vos connaissances sur l’utilisation de ce code ci dessous :
https://www.w3schools.com/charsets/ref_html_8859.as
III)Un Code Unique : Unicode
1)Définition
En 2004, on voit l’apparition d’un code permettant de multiples échanges de texte dans différentes langues aperçu au niveau mondial, on le nomme : La norme Unicode. Il a été développé par le Consortium Unicode(remplace les codages de caractères ou même créer de nouveaux caractères). Ainsi, il est lié a la norme ISO 10646.
A suivre
Aucune réponse