Ouvrir le fichier BORDEAUX matches.csv

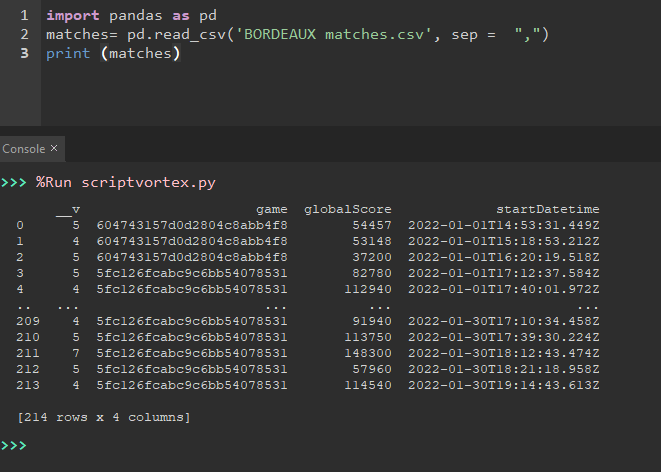
Version google colab:
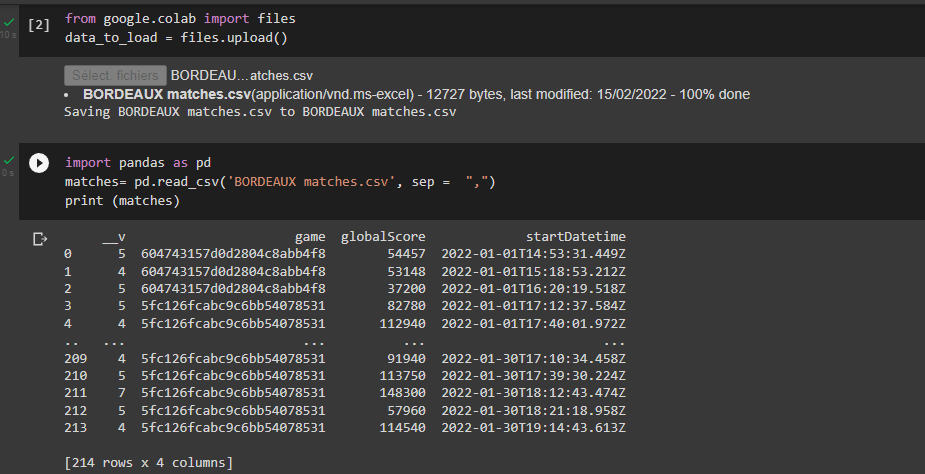
Ce fichier nous donne des informations sur les partie jouées en Janvier à Bordeaux
Une ligne correspond à une partie et le nombre de joueurs constituant l’équipe pour cette partie est donné par la colonne ‘v’.
Grâce à la colonne ‘game’, on peut identifier deux jeux différents
Objectif: Ecrire un programme capable de produire un fichier Excel
> Abréger les données par date avec le nombre de joueurs de parties et le détail pour chacun d’eux. On va s’en servir d’un autre fichier qui définit les codes des jeux:
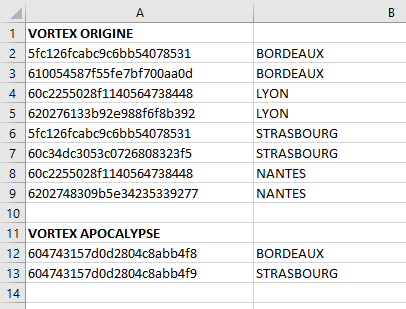
Les étapes:
↦ Importer des fichiers nécessaires
↦ Identifier les jeux
↦ Lire un fichier csv matches.csv
↦ Filtrer les données
↦ Traitement de ‘StartDateTime’ soit en remplaçant une table, soit en créer une autre sans prendre compte l’heure
↦ Séparer les deux tables en fonction du jeu
↦ Agréger par date par rapport à l’exploitation apocalypse
Le lien vers mon colab:
https://colab.research.google.com/drive/1ybyM7ZSGX8LlwUTYVV7WbWRhnel8ENbU?usp=sharing
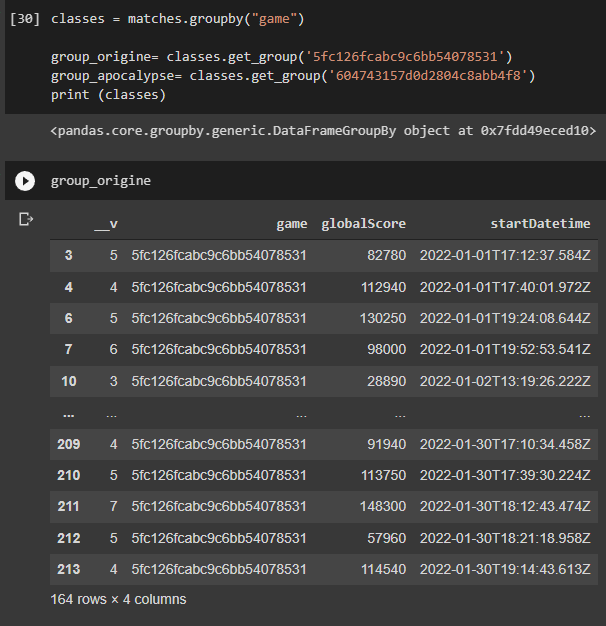

On remarque que ça a bien trié les deux types de jeux. Maintenant on lit le fichier en triant les jeux
On filtre par date:

On a modifié la colonne date en supprimant l’heure:

Correction:
import pandas as pd
from google.colab import files
data_to_load = files.upload()
matches= pd.read_csv(‘BORDEAUX matches.csv’,encoding = « ISO-8859-1 »)
def simplifie_date(val):
return str(val).split(‘T’)[0]
indexNames = matches[matches[‘startDatetime’].isnull()|matches[‘game’].isnull()|matches[‘__v’].isnull()].index
matches.drop(indexNames , inplace=True)
matches[‘date’]=matches[‘startDatetime’].apply(simplifie_date)
matches[‘équipe’]=1
games = matches.groupby(« game »)
origine= games.get_group(‘5fc126fcabc9c6bb54078531’)
apocalypse=games.get_group(‘604743157d0d2804c8abb4f8’)
origine_players=origine.groupby([‘date’])[‘__v’].agg(‘sum’).to_frame()
origine_equipe=origine.groupby([‘date’])[‘équipe’].agg(‘sum’).to_frame()
origine_matches=pd.DataFrame()
origine_players_equipe = pd.merge(origine_players,origine_equipe, on=’date’)
dico={‘__v’:’players_origine’,’équipe’:’equipe_origine’}
origine_players_equipe.rename(columns=dico,inplace=True)
apocalypse_players=apocalypse.groupby([‘date’])[‘__v’].agg(‘sum’).to_frame()
apocalypse_equipe=apocalypse.groupby([‘date’])[‘équipe’].agg(‘sum’).to_frame()
apocalypse_matches=pd.DataFrame()
apocalypse_players_equipe = pd.merge(apocalypse_players,apocalypse_equipe, on=’date’)
apocalypse_players_equipe.rename(columns={‘__v’:’players_apocalypse’,’équipe’:’equipe_apocalypse’},inplace=True)
origine_apocalypse_jour = pd.merge(origine_players_equipe,apocalypse_players_equipe, on=’date’)
origine_apocalypse_jour[‘players’]=origine_apocalypse_jour[‘players_origine’]+origine_apocalypse_jour[‘players_apocalypse’]
origine_apocalypse_jour[‘equipes’]=origine_apocalypse_jour[‘equipe_origine’]+origine_apocalypse_jour[‘equipe_apocalypse’]
origine_apocalypse_jour.to_excel(‘1matches_origine_apocalypse_jour.xlsx’,sheet_name=’bordeaux’)
import matplotlib.pyplot as plt
graphiques=[‘players_origine’,’players_apocalypse’,’players’,’equipe_origine’,’equipe_apocalypse’,’equipes’]
ax=origine_apocalypse_jour.plot(y=graphiques,grid=True,kind= »bar »,figsize=(20,10))
ax.set_ylabel(‘nombre de joueurs par jour’)
ax.set_xlabel(‘date’)
plt.show()
Sous – projet 2
Enlever l’heure de la colonne « Enregistré le »

https://colab.research.google.com/drive/1cFmFQSsANwMNNxTIfQF8vHqQwjHMA5dZ#scrollTo=Njf8kq3o-Fon
solution:
from google.colab import files
data_to_load = files.upload()
# import des librairies
import pandas as pd
import matplotlib.pyplot as plt
# lecture fichier excel
ventes = pd.read_excel('LYON vortex.xlsx',sheet_name='1 6 Détails des ventes')
#Filtrage fichier
ventes.query('Catégorie ==["Réservation","BILLETERIE","CE ET ENTREPRISES"]',inplace=True)
indexNames = ventes[ ventes['Montant TTC'] <0 |ventes['Enregistré le'].isnull()|ventes['Catégorie'].isnull()].index
ventes.drop(indexNames , inplace=True)
#modification de la colonne "enregistré le" et ajout d'une colonne partie
ventes['Enregistré le']=ventes['Enregistré le'].apply(lambda t : t.split()[0])
ventes['partie']=1
#agrégation des lignes par jour avec sommation des quantités
joueurs_par_jour=ventes.groupby(['Enregistré le' ])['Quantité'].agg('sum').to_frame()
#agrégation des lignes par jour avec sommation des parties
parties_par_jour=ventes.groupby(['Enregistré le'])['partie'].agg('sum').to_frame()
#création de 3 lots en fonction du 'produit' vendu
ventes_lot1=ventes.query('Produit ==["VORTEX APOCALYPSE","VORTEX ORIGINE","VORTEX NOEL 12 17 ANS",\
"VORTEX ORIGINE Tarif étudiants","VORTEX APOCALYPSE Tarif Etudiants"]')
joueurs_par_jour_lot1=ventes_lot1.groupby(['Enregistré le' ])['Quantité'].agg('sum').to_frame()
joueurs_par_jour_lot1.rename(columns={'Quantité':"lot1"},inplace=True)
ventes_lot2=ventes.query('Produit ==["RESERVATION GIFT CARD VORTEX ORIGINE","RESERVATION GIFT CARD VORTEX APOCALYPSE"]')
joueurs_par_jour_lot2=ventes_lot2.groupby(['Enregistré le' ])['Quantité'].agg('sum').to_frame()
joueurs_par_jour_lot2.rename(columns={'Quantité':"lot2"},inplace=True)
ventes_lot3=ventes.query('Produit ==["CARTE CADEAU 1E ENTREE","Vortex Team building","Vortex Team Building Privatisation"]')
joueurs_par_jour_lot3=ventes_lot3.groupby(['Enregistré le' ])['Quantité'].agg('sum').to_frame()
joueurs_par_jour_lot3.rename(columns={'Quantité':"lot3"},inplace=True)
#concaténation des trois lots et ajout des valeurs manquantes et du total des lots
stats=pd.concat([joueurs_par_jour_lot1,joueurs_par_jour_lot2,joueurs_par_jour_lot3], ignore_index=False,axis=1)
stats.sort_values(by=['Enregistré le'],inplace=True)
stats.fillna(0,inplace =True)
stats['total']=stats['lot1']+stats['lot2']+stats['lot3']
#visualisation
stats.to_excel('stats.xlsx')
ax=stats.plot(y=['lot1','lot2','lot3'],grid=True,kind="bar",figsize=(20,10))
ax.set_ylabel('nombre de parties par jour')
ax.set_xlabel('date')